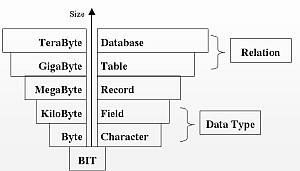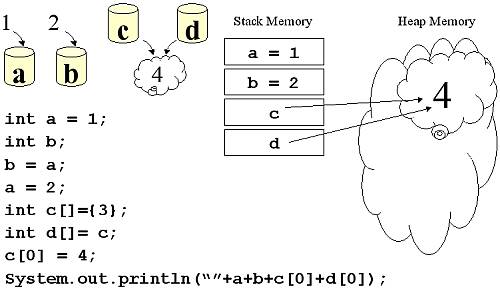
อัลกอริทึม (Algorithm)
การเขียนอัลกอริทึมมี ประเด็นต้องพิจารณาหลายเรื่อง คือ 1)วัตถุประสงค์ 2)เหตุการณ์ก่อนประมวลผล 3)ค่าของพารามิเตอร์ทั้งก่อนและหลังประมวลผล 4)สิ่งที่ได้หลังประมวลผล 5)ลำดับเหตุการณ์ระหว่างประมวลผล
ต.ย. อัลกอริทึมที่ 1 : ต้มมาม่า
1. หามาม่าไว้ 1 ซอง
2. ฉีกซองมาม่าและเทลงถ้วยเปล่า
3. ฉีกซองเครื่องปรุง แล้วเทลงถ้วยเดิม
4. ต้มน้ำให้ร้อนได้ที่ แล้วเทลงถ้วย
5. ปิดฝาไว้ 3 นาที
6. เปิดฝา แล้วรับประทาน
คำถาม : ต้มมาม่า
1. มีขั้นตอนใดสลับกันได้
2. ถ้าเปลี่ยนข้อความ จะเปลี่ยนอย่างไร
3. ถ้าทำหลายถ้วยจะทำอย่างไร
? คน 3 คนใครอายุมากที่สุด และเป็นเท่าใด
ต.ย. อัลกอริทึมที่ 2 : หาค่าเฉลี่ย ใช้ Pseudo Code
1. set variable
2. loop
1. read number into variable
2. add number to total
3. increase counter
3. end loop
4. set average = total / counter
5. print average
|
คำถาม : หาค่าเฉลี่ย
1. เขียนเป็นภาษาไทยอย่างไร
2. แต่ละบรรทัดในจาวาคืออะไร
3. สลับบรรทัดใดในจาวาได้บ้าง
4. ไม่มีตัวแปร avg จะได้หรือไม่
|
1.
2.
3.
4.
5.
|
ภาษาจาวา
byte x;
int i = 0;
int total = 0;
while (i < 5) {
x = System.in.read();
total = total + x;
i++;
}
double avg = total/i;
System.out.println(avg);
|
ปฏิบัติการพื้นฐานของเครื่องคอมพิวเตอร์
โครงสร้างหน่วยความจำ (Memory Architecture)
การจัดสรรหน่วยความจำ (Memory Allocation)
- แบบคงที่ (Static)
- แบบเปลี่ยนแปลงได้ (Dynamic)
ตารางแฟท (FAT = File Allocatio Table)
- Directory Table
- Memory Pointer
File Attribute
- Archive file
- System file
- Readonly file
- Hidden file
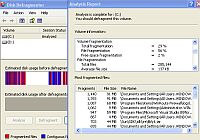
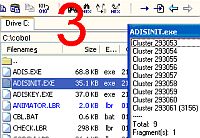
ต.ย. แฟ้ม adisinit.exe มีขนาด 35.1 KB ใช้พื้นที่ 9 Block ๆ ละ 4 KB
เพราะเครื่องนี้แบ่ง 1 Cluster มีขนาด 8 Sectors
ชนิดข้อมูลนามธรรม (Abstract Data Type : ADT)
ชนิดข้อมูลนามธรรม (Abstract Data Type) คือ เครื่องมือกำหนดโครงสร้างข้อมูลที่ประกอบด้วยชนิดของโครงสร้างข้อมูล รูปแบบการดำเนินการ หรือแยกได้ 3 ส่วนคือ รูปแบบข้อมูล (Element) โครงสร้าง (Structure) และ การดำเนินการ (Operations)
|
แบบประเภทข้อมูลตามลักษณะีความสัมพันธ์ในข้อมูล
1. ข้อมูลเชิงเดี่ยว (Atomic Data)
2. ข้อมูลเชิงประกอบ (Composite Data) |
ชนิดข้อมูลนามธรรม (ADT) มิใช้โครงสร้างข้อมูล
แต่เป็นรูปแบบระดับแนวคิดหรือรูปแบบข้อมูลเชิงลอจิคอล
1. รูปแบบข้อมูลเชิงลอจิคอล (Logical Form) เ็ป็นการนิยามด้วย ADT
2. รูปแบบข้อมูลเชิงฟิสิคัล (Psysical Form) เป็นการนำ ADT มาใช้ |
ประสิทธิภาพของอัลกอริทึม (Algorithm Efficiency)
ประเด็นที่ใช้วัดประสิทธิภาพ
1. เวลาที่ใช้ประมวลผล (Running Time)
2. หน่วยความจำที่ใช้ (Memory Requirement)
3. เวลาที่ใช้แปลโปรแกรม (Compile Time)
4. เวลาที่ใช้ติดต่อสื่อสาร (Communication Time)
ปัจจัยที่ส่งผลต่อความเร็วในการประมวลผล
1. ความเร็วของเครื่องคอมพิวเตอร์ (CPU, Main Board)
2. อัลกอริทึมที่ออกแบบเพื่อใช้งาน
3. ประสิทธิภาพของตัวแปลภาษา
4. ชุดคำสั่งที่สั่งประมวลผลเครื่องคอมพิวเตอร์
5. ขนาดของหน่วยความจำในเครื่องคอมพิวเตอร์
6. ขนาดของข้อมูลนำเข้า และผลลัพธ์จากการประมวลผล
- การวัดประสิทธิภาพของอัลกอริทึม (Efficiency Algorihm)
คือ วัดจากพื้นที่ทำงาน และเวลา แต่กับคอมพิวเตอร์ในปัจจุบันที่มีศักยภาพสูง การวัดประสิทธิภาพจากเวลาอาจไม่เห็นความแตกต่าง
- การวิเคราะห์บิ๊กโอ (Big-O Analysis)
คือ การวัดประสิทธิภาพของอัลกอริทึมจากความเร็วในการทำงาน โดยพิจารณาไปที่จำนวนรอบ และเวลา
ปัจจุบันมีการเปลี่ยนจาก f() มาเป็น big-o notaion เพื่อใช้ big-o วัดประสิทธิภาพของอัลกอริทึม
- ขั้นตอนการเปลี่ยน f() เป็น Big-o Notation
1. ปรับฟังก์ชันให้อยู่ในรูปสัมประสิทธิ์อย่างง่าย คือตัดตัวประกอบออก ให้เหลือเพียงค่าของโพลิโนเมียน (คือ n ยกกำลัง)
f(n) = n( (n + 1) / 2 )
= ((1/2)(n ^ 2)) + (1/2(n))
= (n ^ 2) + n
2. ตัดค่าของตัวประกอบออก
= n ^ 2
3. นำฟังก์ชันมาตรฐานมาเขียนในรูปของ Big-o Notation
O(f(n)) = O(n ^ 2)
- ต.ย.1 จงหาผลบวกของการบวกจำนวนที่เริ่มต้นตั้งแต่ 1 - 10
ฟังก์ชัน คือ f(n) = n( (n + 1) / 2 )
= ((1/2)(n ^ 2)) + (1/2(n))
= (n ^ 2) + n
= n ^ 2
O(f(n)) = O(n ^ 2)
- ต.ย.2 จงแปลง f(n) = a*n^k + a*n^k-1 + .. a*n^0 เป็น Big-O Notation
ฟังก์ชัน คือ f(n) = a*n^k + a*n^k-1 + .. a*n^0
= n^k + n^k-1 + .. n^0 (ปรับให้อยู่ในรูปสัมประสิทธิ์อย่างง่าย)
= n^k (ตัดค่าของตัวประกอบออก)
O(f(n)) = O(n ^ k) (เขียนในรูปของ Big-O Notation)
- ต.ย.3 จงแปลง f(n) = 4n + 7 เป็น Big-O Notation
ฟังก์ชัน คือ f(n) = 4n + 7
= n + 7 (ปรับให้อยู่ในรูปสัมประสิทธิ์อย่างง่าย)
= n (ตัดค่าของตัวประกอบออก)
O(f(n)) = O(n) (เขียนในรูปของ Big-O Notation)
- ต.ย.4 จงแปลง f(n) = 1009 เป็น Big-O Notation
ฟังก์ชัน คือ f(n) = 1009
= 1009 (ปรับให้อยู่ในรูปสัมประสิทธิ์อย่างง่าย)
= 1 (ตัดค่าของตัวประกอบออก)
O(f(n)) = O(1) (เขียนในรูปของ Big-O Notation)
การทำซ้ำ หรือลูป มีหลายแบบ
- ลูปแบบเชิงเส้น (Linear Loops)
- ลูปแบบลอการิธมิค (Logarithmic Loops)
- ลูปแบบซ้อน (Nested Loops)
ลูปแบบเชิงเส้น (Linear Loops)
f(n) = n
for (i=0; i< n; i++)
application code
f(n) = n / 2
for (i=0; i< n; i+=2)
application code
ลูปแบบลอการิทึม (Logarithmic Loops)
f(n) = logn
for (i=0; i< n; i*=2)
application code
f(n) = log2n
for (i=0; i< n; i/=2)
application code
ลูปแบบซ้อน (Nest Loops)
ลูปแบบซ้อนชนิดกำลังสอง (Quadratic)
f(n) = n^2
for (i=0; i< n; i++)
for (j=0; j< n; j++)
application code
ลูปแบบซ้อนชนิดลอการิทึมเชิงเส้น (Linear Logarithmic)
f(n) = nlogn
for (i=0; i< n; i++)
for (j=0; j< n; j*=2)
application code
ลูปแบบซ้อนกำลังสองชนิดขึ้นต่อกัน (Dependent Quadratic)
f(n) = n( (n + 1) / 2 )
for (i=0; i< n; i++)
for (j=0; j< i; j++)
application code
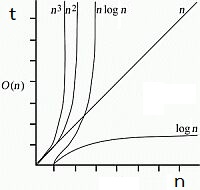
เปรียบเทียมประสิทธิภาพของ Big-O กับความเร็วของยวดยาน ดังนี้
+ O(1) เหมือนเครื่องว๊าบ หรือเครื่องย้ายมวลสาร คือ ไกลแค่ไหนไม่เกี่ยว
+ O(log n) เหมือนเครื่องบินโดยสาร
+ O(n) - เหมือนรถฟอร์มูล่าวัน ระยะทางไกลขึ้น ก็ขับนานขึ้น
+ O(n log n) - เหมือนรถยนตทั่วไป ยิ่งไกลยิ่งช้า
+ O(n^2) - เหมือนมอร์เตอร์ไซด์
+ O(n^3) - เหมือนจักรยาน
+ O(2^n) - เหมือนคนเดิน
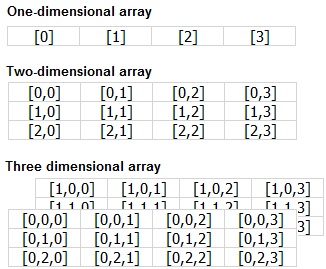
อาร์เรย์ (Array)
คือ ชุดของข้อมูลในชื่อเดียวกันที่มีได้หลายสมาชิก โดยสมาชิกถูกจัดเรียงเป็นลำดับ และมีรูปแบบเป็นแบบใดแบบหนึ่ง
คือ การรวมกลุ่มของตัวแปรที่สามารถใช้ตัวแปรชื่อเดียวกันแทนข้อมูลสมาชิกได้หลาย ๆ ตัวในคราวเีีดียวกัน ด้วยการใช้เลขดรรชนี (Index) หรือซับสคริปต์ (Subscript) เป็นตัวอ้างอิงตำแหน่งสมาชิกบนแถวลำดับนั้น ๆ
- อาร์เรย์หนึ่งมิติ (One Dimension Array)
รูปแบบของอาร์เรย์ คือ arrayname[L:U]
arrayname คือ ชื่อของตัวแปรอาร์เรย์ เช่น x[5]
L คือ ขอบเขตล่างสุด (Lower Bound)
U คือ ขอบเขตบนสุด (Upper Bound)
จำนวนสมาชิก = U - L + 1
- อาร์เรย์สองมิติ (Two Dimension Array)
จำนวนสมาชิก = (U1 - L1 + 1) * (U2 - L2 + 1)
ตัวอย่างอารย์เรย์ ภาษาเบสิก เช่น Dim x(7, 24) As Byte
ตัวอย่างอารย์เรย์ ภาษาซี เช่น int a[][] = new int[4][3];
ตัวแรกมักหมายถึง แถว (rows) ตัวที่สองหมายถึง หลัก (columns)
- เมทริกซ์ คล้ายกับอาร์เรย์ 2 มิติ
- ตำแหน่งในหน่วยความจำ
B คือ ตำแหน่ง หรือแอดเดรสเริ่มต้น (Base Address)
w คือ จำนวนช่องของหน่วยความจำที่จัดเก็บข้อมูลต่อหนึ่งสมาชิก
ตำแหน่งในหน่วยความจำ LOC( a[i] ) คือ B + w (i - L)
เรคอร์ด (Record)
ระเบียนข้อมูล หรือเรคอร์ด
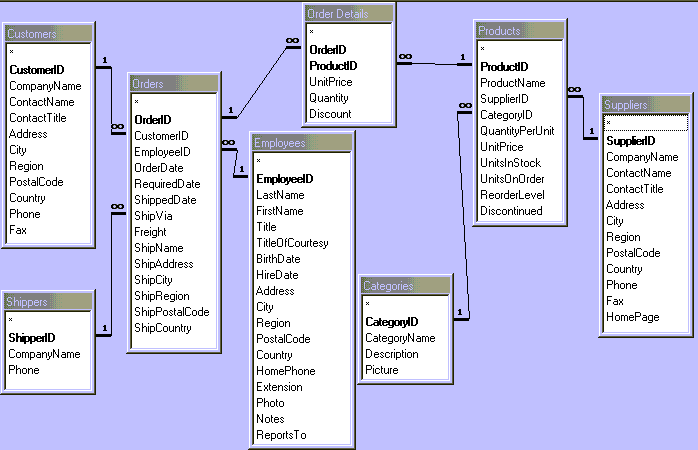
ตารางข้อมูลในฐานข้อมูล NorthWind ประกอบด้วย 8 ตาราง คือ
Categories, Customers, Shippers, Products,
Orders, Order Details, Employees, Suppliers
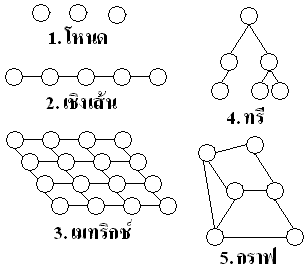
ลิงค์ลิสต์ (Linked List)
ลิสต์ (Lists) หรือรายการ ถือเป็นการจัดเก็บข้อมูลชนิดหนึ่ง ซึ่งข้อมูลเชื่อมต่อกันแบบเชิงเส้น แต่ละข้อมูลมักเรียกว่า อีลิเมนต์ (Element) หรือสมาชิก (Member) โดยแบ่งโดยพื้นฐานได้ 2 แบบคือแบบทั่วไป (General) และแบบจำกัด (Restricted) ซึ่งแนวคิดของลิงค์ลิสต์จะกำหนดให้แต่ละสมาชิกจะประกอบด้วย ข้อมูล (Data) และลิงก์ (Link) โดยข้อมูลอาจประกอบด้วยหลายฟิลด์ก็ได้
การดำเนินงานพื้นฐานของลิสต์ (Basic Operations of List)
1. การแทรก (Insertion)
2. การลบ (Deletion)
3. การปรับปรุง (Updation)
4. การท่องเข้าไปในลิสต์ (Traversal)
ตัวชี้ข้อมูลด้วยภาษาปาสคาล
Binary Tree
type
nodeptr = ^trnode;
trnode = record data : integer; leftptr : nodeptr; rightptr : nodeptr;
end;
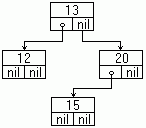 |
ตัวชี้ข้อมูลด้วยภาษาซี
Abstract Data Type ของ คิว
typedef struct node { void* dataptr; struct node* next;
} QUEUE_NODE;
typedef struct { QUEUE_NODE* front; QUEUE_NODE* rear; int count;
} QUEUE;
QUEUE* createQueue (void);
bool enqueue (QUEUE* q, void* itemptr); |
สร้างคิว
var root : nodeptr;
begin
maket(root);
procedure maket(var t:nodeptr);
begin new(t); t^.data := 123; t^.leftptr := nil; t^.rightptr := nil;
end; |
สร้างคิว
QUEUE* createQueue (void) { QUEUE* q; q = (QUEUE*) malloc (sizeof (QUEUE)); if (q) { q->front = NULL; // node ชี้ตัวแรก q->rear = NULL; // node ชี้ตัวสุดท้าย q->count = 0; }
} |
เพิ่มข้อมูลในคิว
new(n);
inserted := false;
o := t;
while not inserted do begin
if num <= o^.data then if o^.leftptr <> nil then o := o^.leftptr; else begin o^.leftptr := n; inserted := true; end
else if o^.rightptr <> nil then o := o^.rightptr; else begin o^.rightptr := n; inserted := true; end;
end;
n^.data := num;
n^.leftptr := nil;
n^.rightptr := nil; |
เพิ่มข้อมูลในคิว
bool enqueue (QUEUE* q, void* itemptr) { QUEUE_NODE* newptr; if (!(newptr = (QUEUE*) malloc (sizeof(QUEUE)))) return false; newptr->dataptr = itemptr; newptr->next = NULL; if (q->count == 0) q->front = newptr; else q->rear->next = newptr; (q->count)++; q->rear = newptr; return true;
} |
สแต็ก (Stack)
- Push คือ เพิ่มข้อมูลลงสแต็ก
- Pop คือ นำข้อมูลบนสุดไปใช้ และลบออกจากสแต็ก
- Stack Top คือ นำข้อมูลบนสุดไปใช้ แต่ไม่ลบออกจากสแต็ก
- Infix คือ นิพจน์ทางคณิตศาสตร์ทั่วไปที่เราใช้กัน
- Postfix คือ นิพจน์ที่โอเปอเรเตอร์อยู่หลังโอเปอแรนต์ เช่น AB+
- Prefix คือ นิพจน์ที่โอเปอเรเตอร์อยู่หน้าโอเปอแรนต์ เช่น +AB
กฎเกณฑ์สำหรับการแปลงนิพจน์ Infix มาเป็นนิพจน์ Postfix [3]p.160
ขั้นตอนที่ 1. ใส่เครื่องหมายวงเล็บให้ทุกนิพจน์ แยกลำดับการคำนวณ เช่น คูณ หาร มาก่อน บวก ลบ
ขั้นตอนที่ 2. เปลี่ยนสัญลักษณ์ Infix ในแต่ละวงเล็บให้มาเป็นสัญลักษณ์แบบ Postfix โดยเริ่มจากวงเล็บในสุดก่อน
ขั้นตอนที่ 3. ถอดวงเล็บออก
ต.ย. 1 A - B / C
ขั้นตอนที่ 1 :
A - (B / C)
ขั้นตอนที่ 2 :
A - (BC /)
A(BC/)-
ขั้นตอนที่ 3 :
ABC/-
คิว(Queue)
- คิว ใน wikipedia.org
ทรี (Tree)
- ทรีใน wikipedia.org
- ไบนารีเสิร์ชทรี (Binary Search Tree)
คือ ทรีที่มีโหนดในซับทรีด้านซ้ายน้อยกว่ารูทโหนด และโหนดในซับทรีด้านขวามีค่ามากกว่าหรือเท่ากับรูทโหนด และซับทรีต้องมีคุณสมบัติเป็นไบนารีเสิร์ชทรี
- เอวีแอลเสิร์ชทรี (AVL Search Tree)
คือ ทรีที่คิดค้นโดย G.M.Adelson-Velskii และ E.M.Landis โดยทรีแบบนี้จะมี ความสูงของซับทรี มาหักลบกันแล้วต้องมีค่าไม่มากกว่า 1
- ฮีพทรี (Heap Tree)
คือ ไบนารีทรีแบบสมบูรณ์หรือเกือบสมบูรณ์ ซึ่งโหนดพ่อจะมีค่ามากกว่าหรือเท่ากบับซับทรีด้านซ้าย และด้านขวา
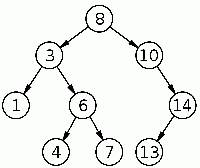 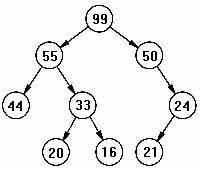
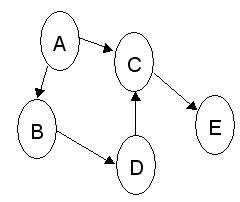
กราฟ (Graph)
การจัดเก็บข้อมูลในกราฟ
1. เมทริกซ์ประชิด (Adjacency Matrix)
2. ลิสต์ประชิด (Adjacency List)
- ดีกรี (Degree) คือ จำนวนของเวอร์เท็กซ์ประชิด
- เอาต์ดีกรี คือ เส้นที่ออกจากเวอร์เท็กซ์
- อินดีกรี คือ เส้นที่เข้ามายังเวอร์เท็กซ์
- เส้นทาง (Path) คือลำดับของเวอร์เท็กซ์ที่ประชิดต่อกันไปยังตัวถัดไป
- เอดจ์ (Edges) คือ เส้นที่เชื่อมระหว่างเวอร์เท็กซ์ แบบไม่มีทิศทาง
- อาร์ค (Arcs) คือ เส้นที่เชื่อมระหว่างเวอร์เท็กซ์ แบบมีทิศทาง
- เวอร์เท็กซ์ (Vertex) คือ โหนด
V = {A,B,C,D,E}
การเรียงลำดับข้อมูล (Sorting)
สำหรับอธิบายการจัดเรียงแบบน้อยไปมาก เป็นการเริ่มต้น
- แบบเลือก (Selection Sort) O(n2)
คือ การสแกนหาค่าน้อยที่สุด แล้วสลับตำแหน่งกับตัวแรก
- แบบฮิพ (Heap Sort)
คือ การย้าย root note ไปอยู่ตำแหน่งสุดท้าย แล้วทำการ reheap ใหม่
- แบบแทรก (Insertion Sort)
คือ การเปรียบเทียบค่ากับตำแหน่งถัดไป หากพบค่าใหม่ก็จะนำมาแทรกในตำแหน่งที่เหมาะสม เหมือนการเรียงไพ่
- แบบฟองสบู่ (Bubble Sort)
คือ เริ่มโหนดสุดท้าย แล้วลอยขึ้นเป็นตัวแรก หากพบตัวใดน้อยกว่าก็จะสลับหน้าที่ในการลอยขึ้นมา
- แบบควิค (Quick Sort)
คือ การจัดเรียงคล้าย Bubble Sort ที่มีการ exchange แต่แบบนี้จะแบ่งส่วนเป็น Partition โดยข้อมูลแบ่งได้ 3 ส่วนคือ
1)ค่า pivot สำหรับแบ่งส่วน 2)ค่าที่น้อยกว่า pivot 3)ค่าที่มากกว่า pivot
1)ก่อนดำเนินการจะนำค่า Pivot Key ตัวแรก และค่าแรก และค่าสุดท้ายมาเรียกให้ถูกต้องก่อน
2)หลังจากนั้น จะย้าย Pivot Key ตัวแรก สลับกับค่าแรก และให้ตัวที่อยู่ถัดค่าแรกเรียกว่า sort left และตัวสุดท้ายเรียกว่า sort right
3)ย้าย sort left ไปทางขวา แล้วย้าย sort right มาทางซ้าย จะหยุด เมื่อ sort left มากกว่า pivot key และ sort right น้อยกว่า pivot key แล้วสลับทั้ง 2 ค่า พร้อมเลื่อนต่อด้วยหลักการเดิม
4)ก่อนเสร็จสิ้นการแบ่ง ให้ย้ายค่าที่เคยเป็นค่าแรก กับ pivot key
5)การดำเนินการหลังแบ่งส่วนแล้ว ให้เริ่มจากด้านซ้าย แล้วค่อยทำทางขวา ในขณะจัดเรียงทางซ้ายก็จะแบ่งส่วนด้วย pivot key ของด้านซ้าย และแบ่งย่อยลงไปอีก ในขณะจัดเรียงทางขวาก็จะแบ่งส่วนด้วย pivot key ของด้านขวา และแบ่งย่อยลงไปอีก ทำเรื่อยไปจนแบ่งส่วนไม่ได้ ก็จะได้ผลการจัดเรียง
การเรียงแบบนี้ปรับปรุงโดย R.C.Singleton ปีค.ศ.1969 ให้เลือกค่า Pivot Key จากค่ากลาง Median Value คือตำแหน่งที่อยู่ตรงกลาง (ตำแหน่งแรก + ตำแหน่งสุดท้าย/2 แล้วปัดเศษทิ้ง)
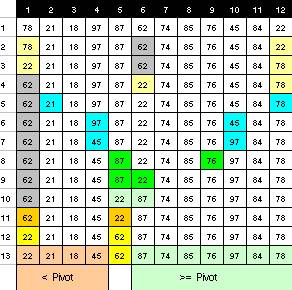
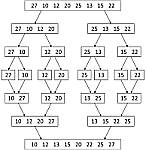
- แบบผสาน (Merge Sort)
คือ การจัดเรียงที่นิยมใช้กับข้อมูลปริมาณมาก ที่ต้องแบ่งข้อมูลออกไปเก็บในหน่วยความจำสำรอง และนำแต่ละส่วนมาจัดเรียงในหน่วยความจำหลัก เช่น ข้อมูล 2 ล้าน 5 แสนระเบียน อาจแบ่งเป็น 3 ส่วน คือ 2 ส่วนแรกส่วนละ 1 ล้านระเบียน ส่วนสุดท้าย 5 แสนระเบียน เพราะข้อจำกัดของหน่วยความจำหลักที่ไม่อาจรับข้อมูลทั้ง 2 ล้าน 5 แสนระเบียนในคราวเดียวกัน เมื่อเรียงแต่ละส่วนจนครบทั้ง 3 ส่วนแล้ว ก็จะนำผลการจัดเรียงมารวมกัน
สำหรับการจัดเรียงจะทำการแบ่งข้อมูลจนเหลือเพียง 2 ส่วน แล้วจัดเรียงกลุ่มเล็กทุกกลุ่มจนหมด แล้วนำทั้งหมดมารวมกัน ก็จะได้ผลการจัดเรียง
 คลิ๊กเพื่อกลับไปหน้าผลงานนักเรียน คลิ๊กเพื่อกลับไปหน้าผลงานนักเรียน
|

 ด้วยความปราถนาดีจาก "สยามทูเว็บดอทคอม" และเพื่อป้องกันการเปิดเว็บไซต์เพื่อหลอกลวงขายของ โปรดตรวจสอบร้านค้าให้แน่ใจก่อนตัดสินใจซื้อของทุกครั้งนะคะ อ่านเพิ่มเติม ...
ด้วยความปราถนาดีจาก "สยามทูเว็บดอทคอม" และเพื่อป้องกันการเปิดเว็บไซต์เพื่อหลอกลวงขายของ โปรดตรวจสอบร้านค้าให้แน่ใจก่อนตัดสินใจซื้อของทุกครั้งนะคะ อ่านเพิ่มเติม ...